Document layout analysis using Multigaussian fit
Laiphangbam Melinda, Raghu Ghanapuram and Chakravarthy Bhagvati
School of Computer and Information Sciences, University of Hyderabad, India
Abstract
This paper proposes a novel technique for layout analysis of documents with complex Manhattan layouts. The technique is designed for Indic script newspapers and works on many types of documents not necessarily with Indic scripts with Manhattan layout. The main idea behind the algorithm is to categorise the physical elements of a document into noise, text, titles and graphics based on their heights. A histogram of heights is computed from the bounding boxes of connected components and a multigaussian fit is used to discover optimal split points between the categories. The gaussian with the highest peak is assumed to correspond to running text. Running text regions are grouped into blocks using nearest neighbour analysis. These initial regions are further refined using a second-level classification of the other elements into graphics, light-coloured text on a dark background, and graphical separators. The resulting layouts show accuracies comparable to some of the best and most popular algorithms such as MHS (winner of ICDAR- RDCL2015 competition) and PRImA’s Aletheia (tool developed by PRImA Research Lab). Results of testing on many Indic script newspapers and other documents, and comparison with Aletheia and MHS on ICDAR dataset show its performance. Our initial results on an Indic document dataset show high performance in identifying running text (> 98%) with an accuracy of 82% on identifying the other elements. Ground truth data for the Indic script newspaper documents is being generated for a more extensive quantitative testing. The strength of our algorithm is that it requires only one parameter - the number of gaussians to fit the height histogram data and is therefore easy to automate and adapt to many documents.
Results
Figure 1(a-e) are the step by step output of the proposed work. (a) Input Image, (b) Binarized image with Connected Components, (c) Height Histogram, (d) Smoothed Gaussians ans (e) Final output
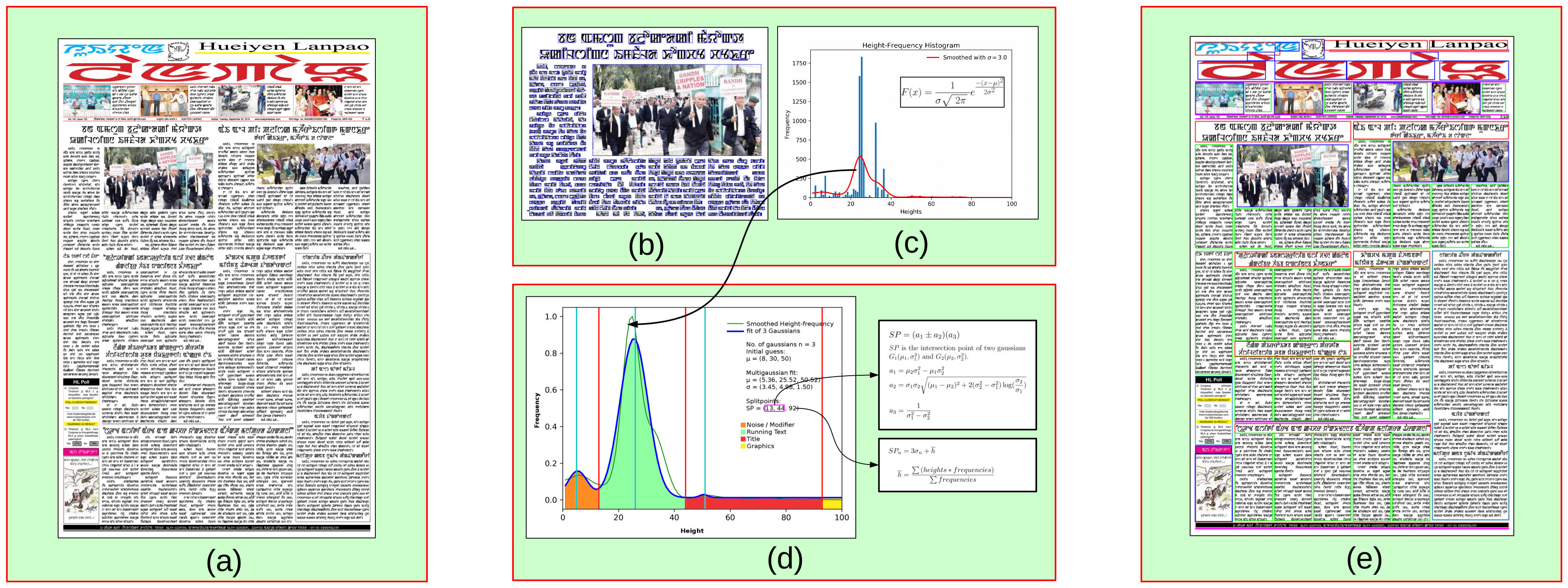
Figure 2 shows the various scripts output.
